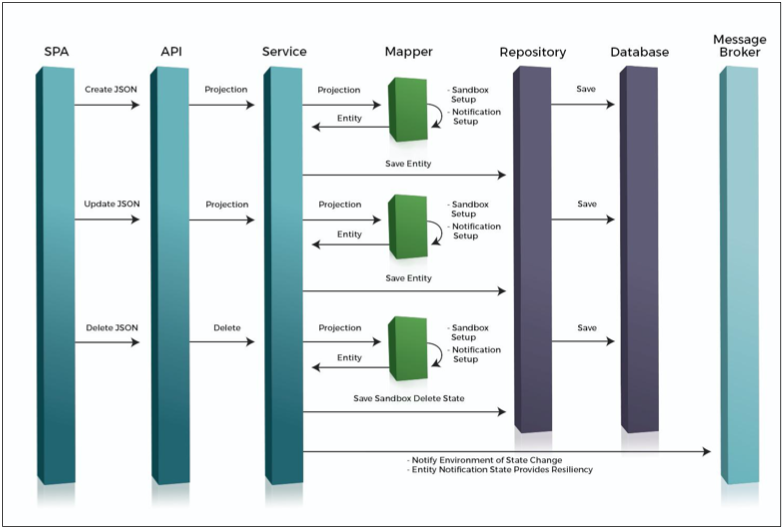
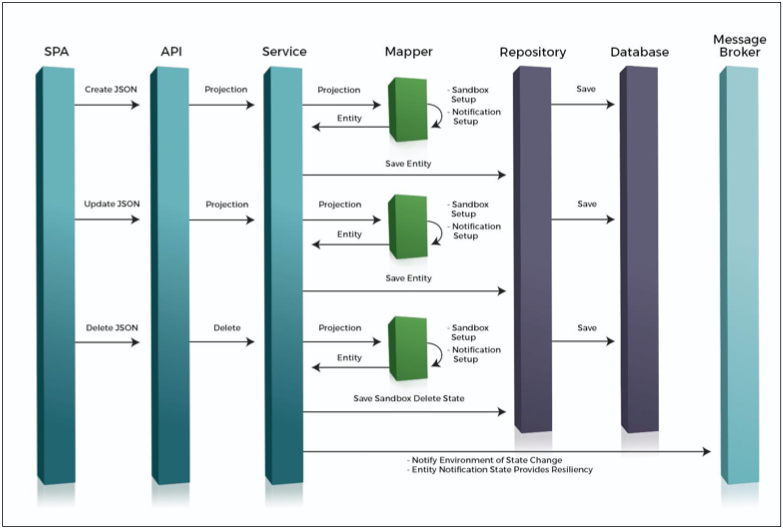
Separate from an explanation of Broadleaf’s Microservice Tech Stack at a high level, it’s worth explaining in a little more detail the anatomy of a Broadleaf Microservice, depicted as follows:
There are a number of components that serve to pass requested information through business logic, then into persistence and message emission. What you see here is a generalization, but the broad strokes remain true for all the microservices we produce. Let's go into some detail about the interactions between each of these components.
Service Anatomy Part 1
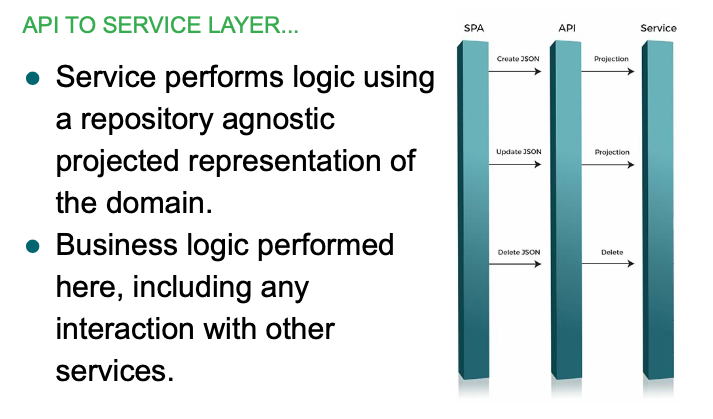
We start with the communication between the presentation tier and the API.
Our APIs are exposed via REST and HTTP. We generally use JSON as the way to describe entities for a RESTful request.
We expose a number of basic fetch APIs to cover every day use cases. We also offer a much more powerful mechanism for ad-hoc query via the API in the form of RSQL support. Through RSQL syntax as part of a request param, the RSQL fragments are converted into real criteria included in database queries during the fetch. This opens up a lot of additional API fetch power without requiring implementation of new API.
We've also added an alternate paging paradigm that allows for stepping forward and backward through large result sets via the API without requiring an additional count query for every page. Those of you familiar with the query demands on paging know that removing the additional count query can be an additional performance lever and we're happy to present this option as part of the framework.
Service Anatomy Part 2
Once the API has received the request, it is passed on to a Spring component for processing. This service component layer is responsible for executing business logic based on the data, possibly communicating with other services.
It is noteworthy here that the structure of the data at this point is platform agnostic. This means that the service component is unaware of how the data will be persisted and doesn't have any JPA specific concerns, for example. It is possible that the persisted structure could be different in a number of ways based on the requirements of the backing platform. However, here at the service component layer, it is primarily interested in a universal projected structure of the data.
Service Anatomy Part 3
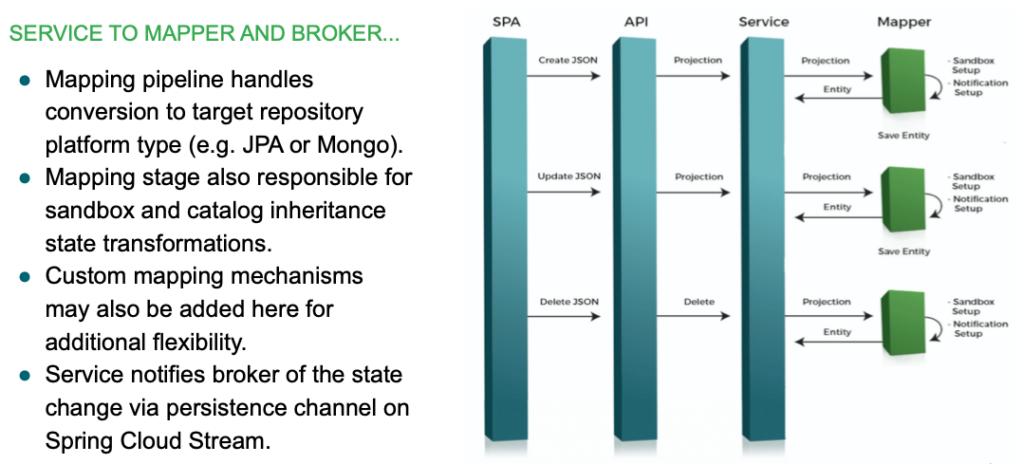
Once the service component is ready to persist the data, it communicates with the mapping pipeline to get a suitable representation ready for persistence in the database.
This pipeline phase is also responsible for managing information on the entity related to sandboxing and catalog state. These pieces of information tend to be leveraged as part of operations initiated by the sandbox and tenant cross-cutting services mentioned earlier.
This pipeline is an open architecture and additional members can be added or tweaked as part of your customizations to mutate out-of-the-box behavior.
And finally, once persisted, the service notifies the broker of the state change. We communicate through Spring Cloud Stream for this over a specific channel.
Service Anatomy Part 4
Finally, once the service component has achieved a ready-to-save state of the data, it requests persistence via the API exposed on the Spring Data repository. The repository is configured through Spring Data to interact with the backing data store and realize the final state of the data in the database.
Customization here continues to be flexible. Repository behavior can be changed or enhanced with custom Spring Data repository fragments that you add. In this way, you can add additional persistence behavior, or override what we ship with out-of-the-box.
Also, this architecture allows Broadleaf to be interoperable with a larger variety of backend database platforms, including a NoSQL option. Broadleaf ships with repository layer providers for JPA to cover classic RDBMS platforms. We also ship with a Mongo repository layer provider to cover the MongoDB platform.
Overall
Microservice architectures are a great way to deliver incremental value quickly and scale performance where you need to.
Broadleaf’s Microservice framework is built on the technologies that developers know and love.
With everything we produce at Broadleaf, extensibility is always a first class citizen, and with our Microservices based framework, we continue that tradition.
We certainly look forward to our Microservice-based framework being used in a variety of solutions worldwide. If you’re ready to join us on the journey, please let us know!