How We Built Scalable Product Recommendations with Apache Spark
Written byElbert Bautista
Published onOct 16, 2025
This service is considered EXPERIMENTAL and is not available for general use. An extended commercial license is needed in order to obtain and use this functionality. Please contact a Broadleaf representative for more details" as mentioned in our docs.
Most eCommerce platforms eventually need product recommendations. The "customers who bought this also bought" features, personalized search results. These aren't nice-to-haves anymore. The problem is your options are usually expensive SaaS platforms or building something custom that falls over once you hit scale.
We wanted something different for Broadleaf: an open system that could handle production traffic, integrate cleanly with our existing microservices, and give teams the flexibility to customize the ML models. Apache Spark turned out to be the right foundation. Here's how we architected it.
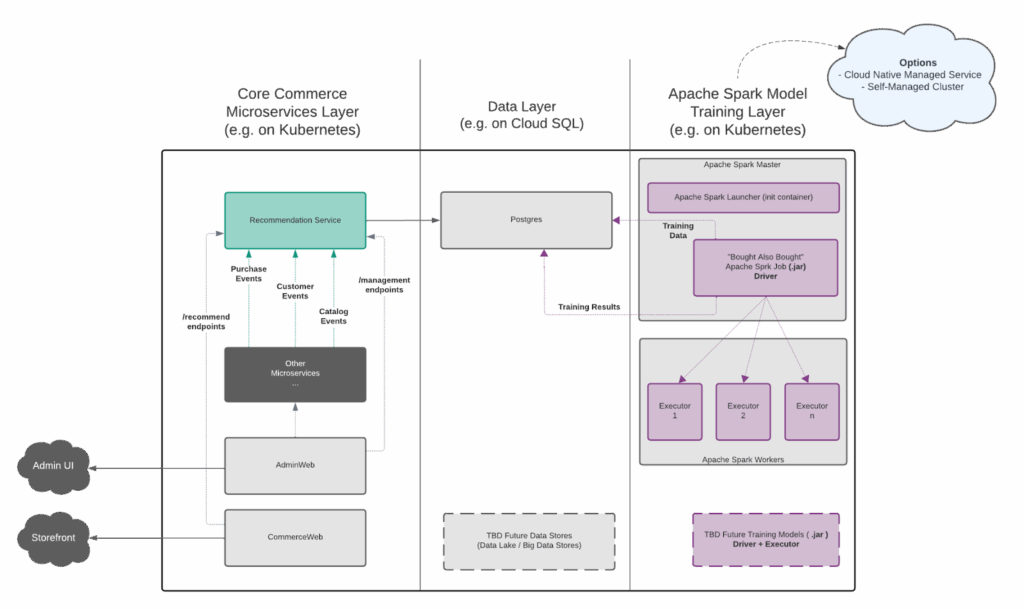
Separating Concerns Into Three Layers
The system breaks down into three distinct responsibilities. The “microservices layer” handles real-time operations, collecting data as events happen and serving recommendations to shoppers. The “data layer” sits in the middle using a configurable data store to capture relevant information such as purchase history to drive generated recommendations.Then there's the “training layer”: this is where Apache Spark processes all that historical data to generate new recommendations.
Collecting Data in Real Time
The Recommendation Engine Service sits in the microservices layer listening to three existing event streams via Spring Cloud Stream bindings. When Catalog Service creates or updates a product, we capture CatalogEntityCreatedEvent and CatalogEntityUpdatedEvent. When Customer Service updates a profile, we process CustomerModifiedEvent. When Order Service processes a purchase, PurchaseEvent flows into our system.
These events flow through our message bus into and stored in the data layer. Purchase data lands in blc_purchase and blc_purchase_item. Product information goes into blc_catalog_item with references tracked in blc_catalog_ref. Customer data populates blc_customer_reference. The schema also supports Broadleaf specific references such as applications, catalogs, and items through blc_application and blc_application_catalog enabling Broadleaf-specific taxonomies and hierarchical data structures.
We made these event streams opt-in rather than auto-enabling them for anyone consuming these libraries so as to make it a conscious decision on which events to process. Catalog events require explicit property flags: allowCatalogEntityCreationNotification, allowCatalogEntityUpdateNotification, and allowCatalogEntityDeleteNotification. Customer events need customer-modified: active: true. This configuration lives in your Spring Cloud Config Service properties.
The reason for opt-in is volume. If you're running a fashion retailer adding 500 new products daily, event-driven syncing might flood your system. Those implementations can switch to scheduled batch jobs that sync catalog data overnight instead. The training pipeline doesn't care how the data arrives, just that it's there when needed. This also means implementations can mix approaches, using events for high-value entities like purchases while batching catalog updates.
One architectural constraint worth noting: we only track purchases with an associated customer_id. Anonymous or guest purchases don't influence the recommendation model. By default this may mean that this may present a “cold start” recommendation problem for new users, but it simplifies the training data and process significantly. As with all things in Broadleaf - the defaults can be tuned and customized as needed.
Training Models Scheduled
By default, training runs on a schedule, usually nightly. A scheduled job in Broadleaf's admin triggers the Spark Launcher, which is a Spring Boot application deployed alongside our Spark cluster. The typical deployment pattern is a sidecar container in Kubernetes. It exposes a single endpoint at /recommendation-engine/train-model that accepts a POST request with the training type.
The Spark Launcher handles the orchestration but doesn't do the computation. When that endpoint gets hit, it uses org.apache.spark.launcher.SparkLauncher to submit a job to the cluster. This is essentially a programmatic wrapper around spark-submit. The launcher injects runtime parameters like data store credentials (pulled from Spring Cloud Config), data store connection strings, and the training model type.
The job artifact is broadleaf-recommendation-engine-bought-also-bought-spark-job along with its dependencies: a Postgres JDBC driver (postgresql-42.7.3.jar), a common library JAR (broadleaf-recommendation-engine-core-lib), and ULID generation utilities (ulidj-1.0.4.jar). If you're running a different database or data store, you'll need to customize the launcher to include the appropriate driver since all Spark executors need it.
The job that runs implements collaborative filtering using Apache Spark's ALS algorithm (Alternating Least Squares) from MLlib. ALS is designed for implicit feedback scenarios where you don't have explicit ratings, just behavioral signals like purchases.
The algorithm doesn't just count how many times products were purchased together. It calculates implicit ratings by looking at the full context. The SparkPurchaseHistoryRecommendationJob class applies boosting to different purchase associations. Products in the same order get a rating boost. Customers in the same segment buying the same product strengthens the signal. Customers from the same account show similar behavior patterns. The timing matters too. Purchases close together in time carry more weight than ones months apart.
These boosting factors are configurable if you extend the job class. The default implementation balances recency with frequency.
ALS decomposes this ratings matrix into latent factors, finding patterns that connect customers to products without requiring explicit feature engineering. The algorithm iterates until convergence, learning which hidden attributes correlate across users and items. The output is straightforward: for each customer, here are the products they're most likely to buy next, ranked by confidence score.
We do recommend some guardrails on the training process. You need at least 300 purchases per application to generate meaningful recommendations. Below that threshold, the sparsity is too high. Keeping sparsity under 99% relative to the user-item matrix as a rule of thumb for relevant recommendations is key. On the high end, we cap processing at 5 million purchases per run, ordered by submit date. Anything older than that gets ignored. This keeps training time reasonable while focusing on recent behavior.
The results are written back to the data store, i.e. blc_user_recommendation which stores one row per customer with metadata about the recommendation set. blc_user_recommendation_item stores the individual recommended products with their rank. After a successful training run, the job truncates both tables and inserts the fresh recommendations. This full-cycle approach means you're always serving current recommendations. The tradeoff is that a failed training run leaves you with no recommendations until the next successful run.
Serving Recommendations Two Ways
Once recommendations exist in the database, the Recommendation Engine Service exposes them through a REST endpoint at /product-recommendations. The endpoint reads the customer context from headers, queries blc_user_recommendation, and joins to blc_user_recommendation_item, then returns the top N items by rank.
Expose the recommendations via widgets in your UI: Content-managed sections can use product fields to surface these recommendations in curated layouts.
Utilize Broadleaf's Search service to modify queries through SolrQueryContributor implementations. With the default recommendation engine enabled, you can add the recommendation-specific contributor that runs as part of the standard search pipeline to boost certain result sets based on what’s returning from the Recommendation Engine. When a search query comes in, the contributor checks if the user context includes a logged-in customer with recommendations. If so, it calls the Recommendation Engine Service to fetch that customer's product IDs, then modifies the Solr query to boost those IDs in the scoring function. An anonymous shopper searching for "running shoes" gets a standard Solr relevance ranking. A logged-in customer who recently bought running gear gets those recommended products ranked higher in the same search. You enable this by setting broadleaf.search.recommendation-engine.enabled: true in your Search service configuration. The contributor is conditional on that flag, so it's not active by default. This allows search results to just work better. Products they're likely to buy naturally appear higher in the list.
How It All Flows Together
A customer completes a purchase. Order Service publishes PurchaseEvent, which the Recommendation Engine Service persists to blc_purchase and blc_purchase_item. At a configurable interval, the scheduled job POSTs to /recommendation-engine/train-model. The Spark Launcher submits the job to the Spark Cluster. Spark executors read the data, run ALS, and write results back to the recommendation tables. Once recommendations are populated, when that customer searches, or visits a page with a recommendations-based content item - their specific recommendations automatically boost relevant products in the results or are shown in the applicable widget.
Each layer operates independently. The Spark cluster scales without affecting the microservices. The microservices handle traffic without waiting for training. The data layer provides the contract between them.
Wrapping Up
The Broadleaf Recommendation Engine is an experimental service that works in conjunction with the rest of the Broadleaf commerce platform. The source for the Spark Launcher and training modules are available so implementations can customize driver dependencies, training parameters, or add new model types beyond “Bought Also Bought”. This Recommendation Engine is meant to be an ideal starting point for implementations looking to build and train their own recommendation-based models using Broadleaf. If you want implementation details, API specs, or deployment guides, check out our developer portal.