Mastering Data Routing in a Microservices World
Written by
Sam
Published on
Feb 13, 2025
Moving from monolithic architectures to microservices has universally changed how applications are built and maintained. In a monolithic system, everything runs together in a single environment, usually relying on one shared database. This makes data management easy but limits flexibility and scalability.
Microservices architecture enhances scalability and modularity by decomposing applications into smaller, independent services concentrating on specific business capabilities. Each microservice also leverages its own independent data source. This allows for faster development cycles and independent deployments. However, it increases deployment complexity.
To make microservices deployments easier to manage, Broadleaf provides a unique concept called Flex Packages. This offers a structured approach to deploying multiple microservices within a single application runtime (JVM), thereby significantly reducing complexity. However, it introduces a critical challenge: how do you maintain the independence of these microservices, especially at the data level, while allowing them to coexist within a shared deployment?
The Need for Data Routing in a Microlith Deployment
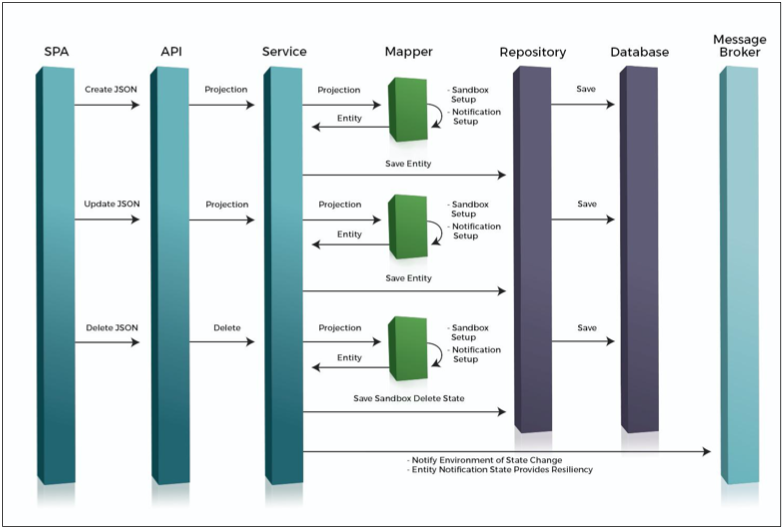
A monolithic system naturally maintains consistency because all services interact with a single shared database. In a "microlith" deployment like Broadleaf's Flex Packages, the runtime is shared between microservices, but the data sources remain distinct. As requests flow through the system, we must ensure strict data isolation so that each service's logic specifically targets its own independent data source and maintains its autonomy.
Without a proper data routing system, microservices operating within a shared deployment could inadvertently access or modify the wrong database, leading to inconsistencies, redundant data storage, and inefficient workflows.
This is where data routing comes in. By intelligently directing database operations to the correct data source based on the request’s context, services can operate independently while maintaining strict data separation within a shared environment.
Data Routing In Practice
A commonly recommended deployment approach in Broadleaf is the Balanced Flex Package.
In this model, services like Catalog, Menu, and Pricing operate within the same deployment unit. Despite sharing the same runtime, the services manage separate data. For example:
- The Catalog Service manages translation data for products and categories.
- The Menu Service maintains translations for menus.
Both services follow the same structured translation framework but store separate translation data—they do not share records.
Additionally, the Tenant Service manages specific system-wide configurations, such as allowed locales, tenant-specific settings, and URL structures, and synchronizes them across services like Catalog and Menu. This ensures that global application configurations remain consistent while preventing unnecessary duplication at the service level.
Without a robust data routing system, this setup would lead to:
- Inconsistencies where updates made in one service don’t reflect in others.
- Manual synchronization adding complexity and increases the risk of errors.
- Redundant data storage, inflating infrastructure costs, and making updates more difficult.
By automating database routing, Broadleaf ensures that each microservice interacts only with its designated database while allowing controlled synchronization of shared application configurations.
Broadleaf’s Data Routing Implementation
A routing data source acts as a mediator between services and databases, adaptively selecting the appropriate data source for real-time interaction.
The Process:
- A request enters the system, and the routing layer identifies the service it originated from.
- The routing data source determines the appropriate database based on this context.
- The decision is stored in a thread-local route context, ensuring that all subsequent database operations within that request follow the same routing path.
- The request is then executed against the correct database, maintaining strict data isolation.
This approach allows multiple microservices to run within a single JVM while maintaining independent data access, eliminating the need for manual database configuration or unnecessary duplication.
Key Components of Broadleaf’s Data Routing Solution
- Thread-local route context – Stores the routing decision for each request to maintain consistency.
- Routing data source – Dynamically selects the correct database based on request context.
- Routable data sources – Represent specific database connections chosen by the routing layer.
- Annotations for route resolution – @DataRouteByKey and @DataRouteByExample define which database should be used per request.
- Microlith-aware shared components – Ensure that services like translation interact with the correct database while avoiding unnecessary duplication.
Conclusion
Data routing is vital in microservices architecture, ensuring that each service connects to the correct database when needed while reducing overall deployment complexity. Without it, data management can quickly become a headache, leading to inefficiencies, inconsistencies, and unnecessary complexity. Broadleaf’s approach simplifies using a routing data source, thread-local contexts, and intelligent routing mechanisms. Organizations can adopt microservices quickly and gradually without the chaos of managing a fully distributed data system from day one.
Broadleaf’s data routing solutions help businesses manage microservices efficiently while maintaining data integrity. Explore our technical documentation or contact our team to learn more about implementation.